
군침이 싹 도는 코딩
Python pandas카테고리컬 데이터 본문
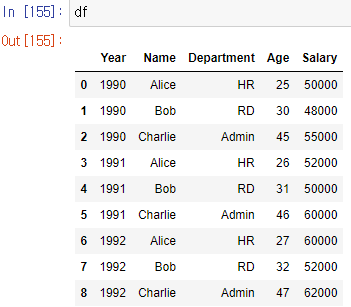
카테고리컬 데이터란 같은 컬럼안에 중복된 데이터가 있는것을 말한다
해당 카테고리컬 데이터를 분석해보자
카테고리컬 데이터에서 칼럼 중복 제거 하는법
df['Year'].unique() # 중복 제거
>>> array([1990, 1991, 1992], dtype=int64)
df['Year'].nunique() # 중복 제거후 갯수
>>> 3# unique() 함수를 이용해 중복된 항목을 제거하고 보여준다.
제거후 갯수만 보고싶으면 앞에 n 을 붙여 nunique를 쓴다
숫자데이터의 통계를 확인하는법

# describe() 함수를 사용해 알수있다 여기서 표기되는것은 숫자데이터만이다
문자열에 describe() 함수를 사용할 경우
df['Name'].describe()
>>> count 9
unique 3
top Alice
freq 3
Name: Name, dtype: object# 그 문자열에서 전체 문자의 갯수 중복제거된 수 가장 많이 사용된 문자열 같은것을 보여준다
카테고리컬 데이터를 데이터별로 묶어서 데이터를 분석하는법
# 각 년도별로, 지급한 연봉 총합을 구하라.
df.groupby('Year')['Salary'].sum()
>>> Year
1990 153000
1991 162000
1992 174000
Name: Salary, dtype: int64
# 각 직원별로 , 얼마씩받았는지 연뵹 평균을 구하세요.
df.groupby('Name')['Salary'].mean()
>>> Name
Alice 54000.0
Bob 50000.0
Charlie 59000.0
Name: Salary, dtype: float64# grouby() 라는 함수를 사용해 년도별 / 직원별로 묶은 후 연봉의 총합 / 평균을 구하였다
연산이 여러개일 경우

# 총합 평균 표준편차를 한번에 구할경우 agg 함수를 사용해 전부 써준다
컬럼에 데이터가 몇개 있는지 확인하는법
# Name 컬럼은 각 이름별로 몇개의 데이터가 있는가
df.groupby('Name')['Name'].count()
>>> Name
Alice 3
Bob 3
Charlie 3
Name: Name, dtype: int64
or
df['Name'].value_counts()
>>> Alice 3
Bob 3
Charlie 3
Name: Name, dtype: int64# 두가지의 방법이 있다. 그룹바이를 사용해 카운트하는법과
컬럼에 억세스하여 벨류카운트를 사용하는법
'Python > Pandas' 카테고리의 다른 글
| Python Pandas apply (0) | 2022.11.25 |
|---|---|
| Python PANDAS OPERATIONS (0) | 2022.11.24 |
| Python pandas NaN 처리 방법 (isna,notna,fillna,dropna) (0) | 2022.11.24 |
| Python pandas csv 파일 불러와 세분화하기 (0) | 2022.11.24 |
| Python pandas 데이터 추가/삭제/변경 (0) | 2022.11.24 |
'Python/Pandas' Related Articles
more



