
군침이 싹 도는 코딩
LinearRegression 본문

경력과 연봉이 있는 데이터 프레임을
리니어 리그레이션으로 모델링 해보자
1. nan 확인
df.isna().sum()
>>> YearsExperience 0
Salary 0
dtype: int64# nan 이 없는것을 확인했다 만약 있다면 값을 바꿔줘야한다
2. X와 y로 분리
X = df.loc[:,'YearsExperience'].to_frame()
y = df['Salary']# X는 경력 y는 연봉
3. 문자열 데이터를 숫자로 바꿔준다.
# 위 데이터 프레임은 문자열이 없으므로 생략
4. 피쳐 스케일링
# 리니어 리그레이션은 자체적으로 피쳐스케일링을 해주기때문에 생략
5. Training / Test 셋으로 분리
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1)
train_test_split 을 import 한다
train_test_split 을 사용하여 트레이닝용 테스트용으로 분리한 4개를 변수로 저장# random_state 는 랜덤의 시드값으로 같은값으로 설정할경우 다른컴퓨터에서도 똑같은 랜덤값이 나온다
6. 모델링한다
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
LinearRegression 을 import 한다
LinearRegression 을 변수 regressor에 저장# 여기서 LinearRegression 을 사용하는 이유는 수치예측을 위해서이다
7. 인공지능을 학습시킨다
regressor.fit(X_train,y_train)
fit 함수를 이용해 분리했던 트레이닝셋을 넣어준다
# 위처럼 결과값이 나오면 성공이다
8. 학습이 끝난 인공지능을 테스트 해본다
regressor.predict(X_test)
>>> array([75074.50510972, 91873.8056381 , 62008.38247653, 81607.56642631,
67608.14931932, 89073.92221671])
y_pred = regressor.predict(X_test)
분리한 테스트셋 X를 predict라는 예측하는 함수에 넣어서 예측값을 구한다
그 값을 y_pred에 저장
9. MSE ( mean squard error) 를 구한다
y_test - y_pred
>>> 17 8013.494890
21 6399.194362
10 1209.617523
19 12332.433574
14 -6497.149319
20 2664.077783
Name: Salary, dtype: float64
error = y_test - y_pred
(error ** 2).mean()
>>> 51338023.49224842
실제값과 예측값을 뺀다
그 값을 error 라는 변수에 저장
error 를 제곱한 뒤 평균을 구한다# 오차가 적을수록 그 인공지능이 유용하다 할수있는데 이를 숫자로 나타내는것이 MSE다
10. 실제값과 예측값을 차트로 그려본다
y_test
>>> 17 83088.0
21 98273.0
10 63218.0
19 93940.0
14 61111.0
20 91738.0
Name: Salary, dtype: float64
y_pred
>>> array([75074.50510972, 91873.8056381 , 62008.38247653, 81607.56642631,
67608.14931932, 89073.92221671])plt.plot(y_test.values)
plt.plot(y_pred)
plt.legend(['Real','Pred'])
plt.show()
실제값은 판다스 시리즈이므로 벨류값만 불러온다
예측값은 넘파이이므로 그대로 사용한다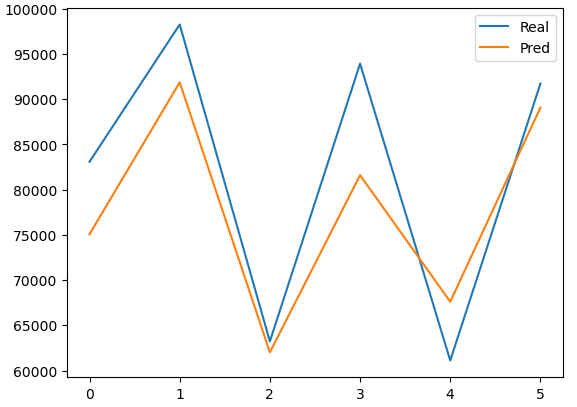
'Python > Machine Learning' 카테고리의 다른 글
| 인공지능 학습 데이터 전처리중 nan 처리 방법 (replace) (0) | 2022.12.02 |
|---|---|
| Logistic Regression (0) | 2022.12.01 |
| 데이터셋을 트레이닝용과 테스트용으로 나누는법 (train_test_split) (0) | 2022.12.01 |
| 피쳐 스케일링 (0) | 2022.12.01 |
| 레이블 인코딩 / 원핫 인코딩 (0) | 2022.12.01 |
'Python/Machine Learning' Related Articles
more


