
군침이 싹 도는 코딩
Decision Tree / Random Forest 본문

Decision Tree 의 알고리즘은 이러하다
어떤 결과값을 가지고 계속해서 이분화하는것이다
이 데이터 프레임으로 구매를 예측하는 디시전 트리를 만들어보겠다
1. nan 을 확인
df.isna().sum()
>>> User ID 0
Gender 0
Age 0
EstimatedSalary 0
Purchased 0
dtype: int64
2. X,y 를 나눈다
y = df['Purchased']
X = df.loc[:,'Age':'EstimatedSalary']
3. 피쳐 스케일링 해준다
from sklearn.preprocessing import MinMaxScaler
scaler_X = MinMaxScaler()
X = scaler_X.fit_transform(X.values)# y는 이미 0과 1이므로 따로 피쳐 스케일링 할 필요가 없다
4. 트레이닝,테스트셋으로 나눠준다
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=1)
5.모델링 및 학습
from sklearn.tree import DecisionTreeClassifier
classifier = DecisionTreeClassifier(random_state=1)
classifier.fit(X_train,y_train)
6. 테스트 및 검증
y_pred=classifier.predict(X_test)
from sklearn.metrics import confusion_matrix, accuracy_score
cm = confusion_matrix(y_test,y_pred)
cm
>>> array([[51, 7],
[ 8, 34]], dtype=int64)
accuracy_score(y_test,y_pred)
>>> 0.85
7. 시각화
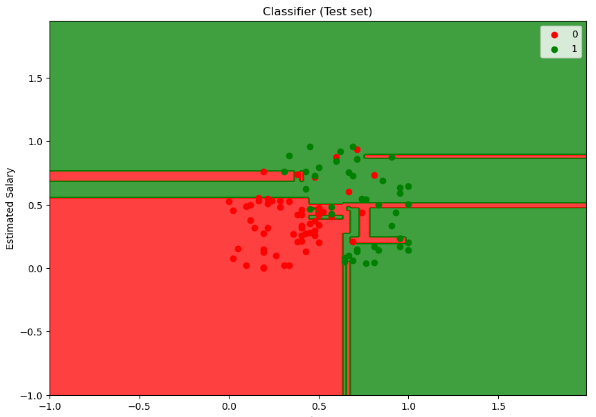
# 디시전 트리의 성능을 개선한 모델이 있다
그것이 바로 Random Forest로 이것은 디시전 트리를 여러개를 생성한다
다른 부분만 코드블럭으로 따로 표기한다
from sklearn.ensemble import RandomForestClassifier
classifier2 = RandomForestClassifier(n_estimators=100)# 랜덤포레스트에 임폴트 해주고
랜덤 포레스트를 변수에 저장할때 파라미터로 디시전 트리를 몇개나 만들지 지정할수있다
디폴트 값은 100이다
'Python > Machine Learning' 카테고리의 다른 글
| Hierarchical clustering (0) | 2022.12.05 |
|---|---|
| K-Means clustering (0) | 2022.12.02 |
| Grid Search (0) | 2022.12.02 |
| Support Vector Machine (0) | 2022.12.02 |
| K-NN (0) | 2022.12.02 |
'Python/Machine Learning' Related Articles
more



