
군침이 싹 도는 코딩
K-Means clustering 본문

동작원리는 먼저 그룹을 몇개로 나눈다음 각 그룹의 중심점을 랜덤으로 잡고
그 중심점을 기준으로 선을 그어 영역을 나눈다 그 영역안을 자신의 색깔로 바꾸고
그 영역안의 중심점을 또 찾아 중심점이 이동한다 이러한 방식을 무한반복하는것이다.
주로 그루핑을 할때 사용한다
이 데이터프레임으로 K-means를 해보겠다
1. nan 을 확인
df.isna().sum()
>>> CustomerID 0
Genre 0
Age 0
Annual Income (k$) 0
Spending Score (1-100) 0
dtype: int64
2. X,y 값을 세팅
X = df.iloc[:,3:]
X
# X의 값만 세팅한 이유는 언수퍼바이즈드 러닝에서는 y값이 없기때문이다
따라서 분류나 수치예측이 아니기때문에 피쳐 스케일링도 필요없다
3. 모델링
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters= 3,random_state=2)
# n_clusters= 여기에 몇개의 그룹으로 할지 설정해줄수있다
# random_state= 이것은 랜덤값을 맞추는 파라미터다
4. 결과 및 결과값을 다시 데이터프레임에 저장
y_pred = kmeans.fit_predict(X)
# 여기서는 다른 머신러닝과 다르게 predict 대신 fit_predict를 사용한다
df['Group'] = y_pred
df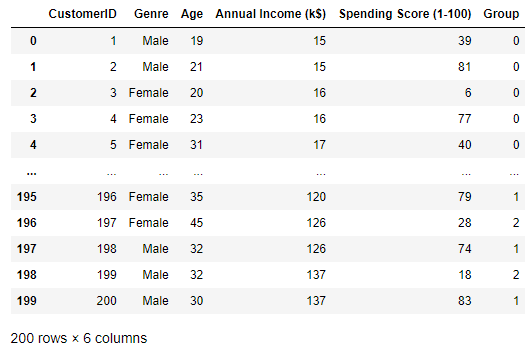
# 데이터 프레임에 그룹이라는 컬럼으로 그루핑된것을 확인할수있다
'Python > Machine Learning' 카테고리의 다른 글
| Hierarchical clustering (0) | 2022.12.05 |
|---|---|
| Decision Tree / Random Forest (0) | 2022.12.02 |
| Grid Search (0) | 2022.12.02 |
| Support Vector Machine (0) | 2022.12.02 |
| K-NN (0) | 2022.12.02 |
'Python/Machine Learning' Related Articles
more



